WebhookとAPIの違いとは?負荷・セキュリティ・運用監視の面から徹底比較

WebhookとAPIは、どちらもシステム間の連携を実現する技術ですが、その仕組みと特性には大きな違いがあります。開発の際にはこれらの違いを理解して適切に使い分ける必要があります。本記事では、WebhookとAPIの技術的な違いを深掘りし、それぞれの適切な使い分け方を解説します。

目次
WebhookとAPIの違い
WebhookとAPIの違いは、大きく以下の3つのポイントに集約されます。
- プッシュ型とプル型
- レイテンシとネットワーク負荷
- セキュリティの実装方法
プッシュ型とプル型
WebhookとAPIの最も大きな違いは、通信方式にあります。
Webhookはプッシュ型の通信で、サーバーからクライアントへ自動的にデータを送ります。例えば、blastengineの場合、メールのドロップやエラーを検知するとblastengineのサーバーがクライアント側のシステムへ即座に通知を送ります。
一方、APIはプル型でクライアント側が必要なタイミングでサーバーにデータを取得しに行きます。もしドロップやエラーの発生状況をAPI経由で取得するなら、クライアント側でポーリング(定期的な問い合わせ)が必要になります。
この違いはシステム設計において非常に重要な検討ポイントです。
レイテンシとネットワーク負荷の違い
Webhookはイベントが発生するとすぐに通知を送るため、APIポーリングと比べてレイテンシが低いという大きなメリットがあります。例えば、メールのドロップやエラーが発生した直後に通知を受け取れるため、リアルタイム性が求められるシステムに適しています。また、イベントが発生したときだけ通信が行われるのでネットワーク負荷も抑えられます。
一方、APIポーリングでは一定間隔でサーバーにリクエストを送るため、イベントが発生してから検知するまでに遅延が生じる場合があります。レイテンシを低減するためにはポーリング間隔を短くする必要がありますが、その分リクエストの回数が増えネットワーク負荷は高まります。
ただし、これはイベントの発生頻度やWebhookの仕様にもよります。例えば、1秒間に100回のイベントが発生する場合、Webhookで1イベントごとに通知すると1秒あたり100回の通信が発生します。しかし、APIポーリングであれば1秒ごとのリクエストでその1秒間に発生した100件のイベントをまとめて取得できるため、Webhookよりも通信負荷が低くなるケースもあります。
システム設計ではイベントの発生頻度や求めるリアルタイム性を考慮し、どちらの方式が適しているかを見極めることが大切です。なお、blastengineのWebhookは複数イベントをまとめて通知できる仕様になっており、通信の増加を抑えられる工夫がされています。
セキュリティ実装の違い
WebhookとAPIでは、セキュリティの実装方法も異なります。
| 手法 | 検証対象 | 検証する側 |
|---|---|---|
| API | OAuth、JWT、APIキー | クライアント |
| Webhook | 署名検証、IP制限、シークレットトークン | サーバー |
特にWebhookでは、受信したデータが正規の送信元から送られたものかを検証するために、署名検証やBasic認証などが重要です。また、冪等性(同じリクエストが複数届いても問題が起きないようにする)を確保するため、冪等性トークンを利用する実装も推奨されます。
APIの場合、このような重複排除の責務はクライアント側に委ねられることが多いです。また、セキュリティにおける責任範囲も異なり、APIではサーバー側が認証・認可の大部分を担当する一方、Webhookではクライアント側(Webhook受信側)が検証を担うことになります。
この責務の違いをきちんと理解し、それぞれの特性に合わせたセキュリティ対策を実装することが安全なシステム構築の鍵と言えるでしょう。
なぜAPIポーリングのほうがネットワーク負荷が高くなるのか
WebhookよりもAPIポーリングの方がネットワーク負荷が高くなりやすい理由には、主に以下の3つの要因があります。
- 通信が発生する要因の違い
- 空振りリクエストの有無の違い
- リトライ戦略の違い
それぞれの要因について、以下の表にまとめました。ぜひご覧ください。
| 観点 | APIポーリング | Webhook | 備考 |
|---|---|---|---|
| 通信トリガー | 定期的なポーリング(時間駆動) | イベント発生時のみ(イベント駆動) | 通信そのものの起点(トリガー)が異なる |
| 空振りの有無 | あり | なし | 通信エラー時のリトライを空振りに含まない場合 |
| トラフィックの増加要因 | クライアント数 × 1時間あたりポーリング数 × ポーリング間隔 | イベント数 × エラー率 × リトライ回数 | APIは常時リクエストが発生し続ける。Webhookは例外時のみ増加。 |
| 通信スパイクの発生タイミング | 通常運用時(大量クライアントの同時アクセス) | サーバーダウン等でリトライが連続発生する場合のみ | スパイクの起点が異なる |
| リトライ制御の主体 | クライアント | 送信元サーバー | 制御責任の所在が逆 |
| 主なリトライ戦略 | 指数バックオフ+ジッター+サーキットブレーカ | 指数バックオフ+ACK応答+DLQ(失敗通知保存) | 共に指数バックオフを使用するが、使われ方が異なる |
| 帯域使用の効率性 | 比較的低い(空振り+常時通信) | 比較的高い(意味のある通信のみ) | 帯域に対する通知の有効性で明確な差がある |
| 負荷平準化のための工夫 | ジッター、シャーディング等 | 不要(設計上トラフィック集中が起きにくい) | Webhookは構造的に負荷分散されやすい |
実際にどのくらいネットワーク負荷の差が生じるか
WebhookとAPIポーリングのネットワーク負荷の差は、実際の運用環境では想像以上に大きくなることがあります。では、この差がシステム全体のパフォーマンスやコストにどのような影響を及ぼすのか、実験を通して具体的に見ていきましょう。
実験の方法
WebhookとAPIのネットワーク負荷の差を定量的に評価するため、ローカル仮想環境を使って以下のような実験を行いました。
【実験の目的】
・同じシナリオでAPIポーリングとWebhookのネットワーク負荷やレイテンシを比較する
【共通条件】
・1時間あたりにイベント20回程度が発生
・PrometheusとGrafanaでメトリクスを収集・可視化
・すべてDocker Compose上で構築し、各コンテナ間はローカル仮想ネットワークで通信
各コンポーネントの構成
■ APIの構成
| コンポーネント | 役割 |
|---|---|
| poll-api | APIサーバー。175秒ごとにイベント(タイムスタンプ)を発生させ、クライアントのポーリング時に返却。イベント発生から取得までのレイテンシを記録。 |
| poll-client | 30秒間隔でpoll-apiへアクセスするクライアント。Pushgateway経由でPrometheusにメトリクスを送信。 |
| メトリクス | poll_e2e_latency_seconds: イベント発生から取得までの平均秒数http_request_total: poll-clientからpoll-apiへのGETリクエスト総数 |
■ Webhookの構成
| コンポーネント | 役割 |
|---|---|
| webhook-sender | 180秒ごとに1回、Webhookリクエスト(POST)を送信。 |
| webhook-receiver | Webhookサーバー。POST受信時に現在時刻を取得し、ts_emit(発生時刻)との差で遅延を計測。 |
| メトリクス | webhook_e2e_latency_seconds: イベント発生(送信)から受信完了までの平均秒数http_request_total: webhook-senderからwebhook-receiverへのPOSTリクエスト総数 |
この構成で1時間稼働させ、各メトリクスを収集しました。
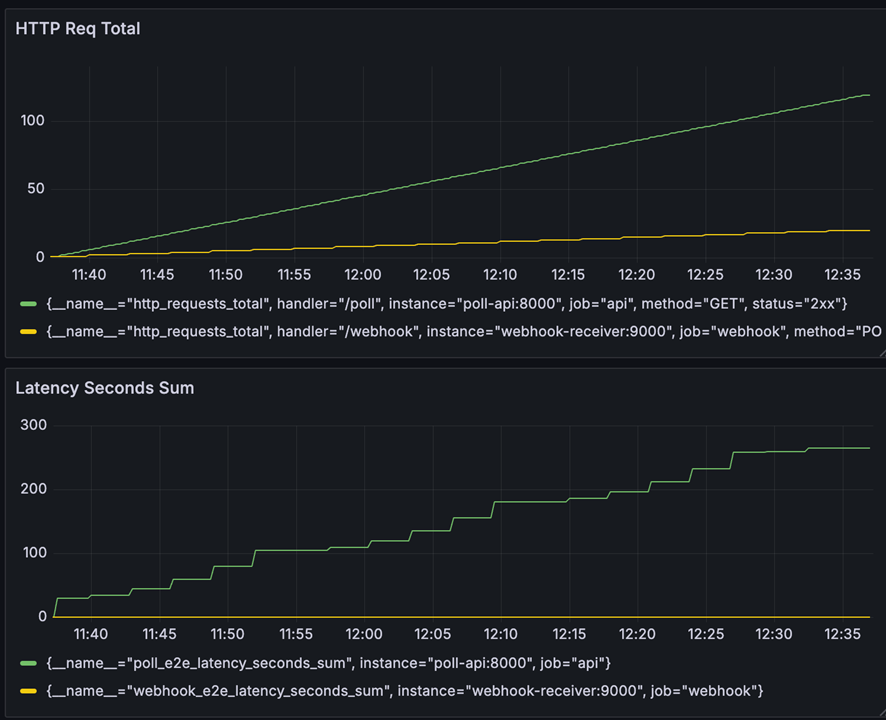
実験結果
- API側の結果
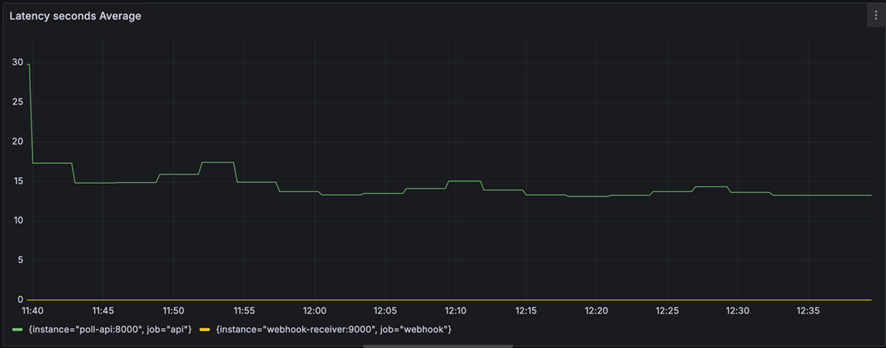
- poll_e2e_latency_seconds: 平均13.2秒
- ・http_request_total: 119回
- Webhook側の結果
- webhook_e2e_latency_seconds: 平均0.0096秒
- http_request_total: 20回
考察
今回のように、1時間あたりイベントが20回発生する程度の頻度でも、リクエスト数やレイテンシはWebhook方式の方が圧倒的に少ないという結果になりました。なお、今回はローカル環境での実験のため、実運用ではRTT(往復遅延時間)がさらに上乗せされ、両者の差がもっと開く可能性があります。
またAPIポーリングでは、平均して13秒程度のレイテンシが発生しており、ビジネスロジックの内容によっては「間に合わない」というケースも考えられます。レイテンシを減らすにはポーリング間隔を短くする必要がありますが、それには大きなトレードオフがあります。
例えば、ポーリング間隔を0.5秒まで短縮してみたところ、レイテンシは平均で0.25秒程度にまで減少しました。しかし、下記のグラフの通り、間隔を短くしたぶんHTTPリクエスト数が大幅に増え、ネットワークへの負荷が急増してしまいました。

今回の実験からも、今回のような条件下ではAPIポーリングよりWebhookの方がネットワーク負荷の面で適していることが、改めて確認できました。
APIとWebhookのセキュリティ対策の違い
APIとWebhookのセキュリティ対策は、その通信モデルの違いによってアプローチが大きく異なります。ここでは、両者それぞれのセキュリティリスクや対策について詳しく見ていきましょう。
Webhook特有の攻撃方法と対策
Webhookは外部からのHTTP POSTリクエストを受け付ける仕組みのため、特有のセキュリティリスクにさらされやすいという側面があります。例えば代表的な攻撃手法とその対策は、以下の通りです。
| 脅威 | 攻撃の内容 | 対策方法 |
|---|---|---|
| 送信元のなりすまし | 攻撃者が正規のサービスになりすまし、偽のデータを送信する。 | Basic認証、HMAC署名検証 |
| DoS攻撃 | 攻撃者が大量のリクエストを送ってサーバーのリソースを枯渇させる。 | IPホワイトリスト制限 |
| リトライを悪用した妨害 | 攻撃者が受信側になりすまして2xx以外の応答を返し、リトライを増加させる。 | リトライ回数や頻度に制限を設ける |
実際の運用では、HMAC署名検証とIPアドレス制限をセットで実装することが基本的な対策となります。加えて、以下のような対策も考慮すべきです。
- レート制限の導入
- Webhookペイロードのサイズ制限
- Webhook受信先エンドポイントの非公開化
こうした対策を多層的に組み合わせることで、Webhook特有の脆弱性から自社システムをしっかりと守ることができます。
API特有の攻撃方法と対策
APIは認証を前提とした設計になっているため、攻撃者はAPIキーの漏えいや権限スコープを超えたアクセスを狙ってきます。例えば代表的な攻撃手法とその対策は、以下の通りです。
| 脅威 | 攻撃の内容 | 対策方法 |
|---|---|---|
| APIキーの盗難 | 実装者が意図せずに流出させたAPIキーを攻撃者が入手する。 | APIキーの適切な管理、権限設計の見直し |
| インジェクション攻撃 | APIのパラメータに悪意あるコードを注入する。 | バリデーションの徹底 |
| DDoS攻撃 | 攻撃者が大量のリクエストを送り、サーバーリソースを枯渇させる。 | レート制限の実装 |
| ブルートフォース攻撃 | APIキーやトークンを総当たりで試行する。 | レート制限、CAPTCHAの導入 |
定期的なセキュリティ監査やAPIキーのローテーションも重要です。これらを組み合わせて実装することで、APIのセキュリティリスクを大幅に軽減することができます。
共通のセキュリティ対策
WebhookとAPIの両方に共通するセキュリティ対策も存在します。例えば以下のような対策が挙げられます。
| 対策 | 内容 | 防止できる攻撃方法 |
|---|---|---|
| 通信の暗号化(HTTPS) | 最低でもTLS 1.2以上を利用する。 | 通信の盗聴や改ざん |
| 認証 | APIキーやOAuth 2.0、JWTを活用する。 | 不正アクセス |
| WAF導入 | Web Application Firewallを設置する。 | DDoS、ブルートフォース |
| 入力データ検証 | JSONスキーマバリデーションやパラメータの型チェックを行う。 | SQLインジェクション、XSSなど |
| ログ監視 | アクセスログや監査ログを定期的に確認する。 | 不正侵入の早期発見 |
加えて、以下のポイントも非常に大切です。
- 定期的な脆弱性スキャンやペネトレーションテストの実施
- セキュリティインシデント発生時の対応手順を策定し、チーム内で共有する
これらの対策を総合的に実施することで、WebhookとAPI双方の安全性を高め、安心してシステム運用を続けることができるのです。
リトライ設計とエラーハンドリングの違い
WebhookとAPIでは、通信失敗時のリトライ設計やエラーハンドリングの考え方が根本的に異なります。ここでは、両者のリトライ戦略の違いについて詳しく見ていきましょう。
| 項目 | Webhookのリトライ戦略 | APIのリトライ/ポーリング戦略 |
|---|---|---|
| 主導権 | 送信元システム | クライアント側 |
| リトライの目的 | 一時的な障害からの回復 | 一時的な障害からの回復 |
| 標準のリトライ回数 | 3〜5回 | 再試行上限を設定(無限ループ禁止) |
| リトライ間隔 | 指数バックオフ(指数的に増加) | 指数バックオフ(指数的に増加) |
| 冪等性対応 | リクエストIDなどで重複排除が必要 | リクエストIDなどで重複排除が必要 |
| 永続失敗時の対応 | デッドレターキューで保存・手動再処理 | エラー内容を解析して恒久障害を識別 |
| サーバー指示への対応 | 該当なし(受信側が主に対応) | Retry-After ヘッダに従う |
| 特有の懸念 | 同一イベントの重複通知 | ポーリング間隔の最適化 |
| 負荷対策 | リトライ間隔を空けて負荷軽減 | ポーリング間隔調整 |
| 重要な設計観点 | 信頼性向上・再送制御・冪等性 | 障害の種類別処理・サーバー負荷管理 |
Webhookのリトライ戦略
Webhookでは、送信元システムが通知に失敗した際、自動的にリトライを行う設計が一般的です。多くのサービスでは、再試行は3〜5回程度が標準であり、指数バックオフ方式(時間間隔を徐々に広げる方法)が採用されています。ただし、Webhookでは以下のような課題も考慮する必要があります。
- 同一イベントが複数回届く可能性があるため、リクエストIDなどを使った冪等性(重複排除)の確保が必須
- 一時的に受信側が利用できない場合に備え、デッドレターキューを用意することが重要
こうしたリトライ戦略をしっかりと設計することで、Webhookシステムの信頼性を大きく高めることができます。
APIのリトライ/ポーリング戦略
APIでは、クライアント側が主導権を持ってリトライを行うことが大きな特徴です。基本的には、サーバー側の5xxエラーやタイムアウトが発生した場合のみ再試行を行い、4xxエラー(クライアントエラー)に対しては再試行しないことが推奨されます。
再試行間隔には、サーバーへの負荷を抑えるために指数バックオフ方式が用いられることが多いです。また、サーバーから「Retry-After」ヘッダが返された場合には、それに従うことも重要です。
ポーリング戦略においては適切な間隔設定が非常に重要です。短すぎるとサーバーに過剰な負荷がかかり、長すぎるとリアルタイム性が損なわれてしまいます。無限にリトライを続けることは避け、最大再試行回数を設定することが障害時の影響を最小限に抑えるポイントです。
さらに、エラー応答をきちんと解析し、一時的な障害か永続的な問題かを見極めるロジックを実装しておくと、より堅牢で賢いリトライ戦略になります。
例えば以下のような対応が効果的です。
- 5xx系のエラーのみを再試行の対象にする
- 「Retry-After」ヘッダの有無を確認して適切な待機時間を設定する
- 冪等性を保つためにリクエストIDを付与する
運用監視とアラート設計の違い
WebhookとAPIでは、運用監視やアラート設計において基本的な考え方や注目すべきポイントが異なります。ここでは、それぞれの違いを詳しく見ていきましょう。
| 項目 | Webhookの運用監視 | APIの運用監視 | 共通監視ポイント |
|---|---|---|---|
| 監視対象の主眼 | 受信側での失敗や異常検知 | 提供側の応答性能と健全性 | サーバーやシステム全体の負荷と異常検知 |
| 特に注目すべき指標 | 署名検証失敗数ACK未返却によるリトライ数4xx/5xxエラー比率エンドポイント応答時間 | 5xxエラー率ポーリング成功率P95レイテンシレート制限到達/スロットリング回数 | CPU/メモリ負荷接続数の急増リリース後のエラー率上昇 |
| 主なアラートトリガー | 不正アクセスの兆候リトライ急増による障害兆候継続的な受信エラー | エラー率5%以上レイテンシ閾値超過(例:500ms)正常応答の低下 | DoS攻撃兆候(接続数)高負荷状態新機能導入後の不具合 |
| 備えるべき仕組み | デッドレターキューの活用応答ログの分析 | 監視ツール(CloudWatch/Datadog等)によるメトリクス収集と通知 | 常時表示のダッシュボード自動アラート通知設定 |
| 運用の目的 | システム間連携の信頼性確保 | クライアント体験・API健全性維持 | システム安定稼働の前提条件の維持 |
Webhook運用監視のポイント
Webhookの運用監視ではイベント受信の確実性を担保するための仕組み作りが重要です。まず注目すべきなのは、署名検証失敗の回数です。この数値が急増している場合、不正アクセスの試みや設定ミスの可能性が考えられるため、即座にアラートを上げられる体制を構築する必要があります。
また、ACK(確認応答)が返らずにリトライが増えている場合も注意が必要です。これは、サーバー負荷の増大や一時的なネットワーク障害の兆候である可能性があります。
特に重要なのは受信エラーの発生率です。5xxエラーが継続的に発生している場合は自社側のシステム問題が疑われ、4xxエラーが多発する場合はWebhook設定や認証情報の再確認が必要です。
さらに、エンドポイントごとの応答時間を監視しパフォーマンス低下を早期に検知することも大切です。デッドレターキューを用意して処理に失敗したイベントを保存し、後から分析できる体制を整えることも運用の安定化に大いに役立ちます。
例えば、Webhook監視の際には以下のようなポイントを重点的にチェックするとよいでしょう。
- 署名検証失敗の急増
- ACK未返却によるリトライ回数の増加
- 4xx/5xxエラーの発生率
- エンドポイント応答時間の変動
これらのポイントを押さえた監視体制を整えることで、Webhookを使ったシステム間連携の信頼性をしっかり確保できます。
API運用監視のポイント
APIの運用監視ではサービス全体の健全性を継続的に把握することが重要です。特に注目すべきなのは「エラー率」、中でも5xxエラーの頻度です。5xxエラーが増えると、APIサービスそのものに問題が発生している可能性が高いため即座の対応が求められます。
次に「ポーリング成功率」の監視も欠かせません。この値が低下すると、クライアントがデータを正常に取得できなくなり、ユーザー体験に直結した影響が出ます。
「P95レイテンシ」も重要な指標です。これは全リクエストのうち95%が完了するまでの処理時間を示し、パフォーマンスを評価する際の重要な指標となります。
CloudWatchやDatadogなどの監視ツールを利用すれば、これらの監視は比較的簡単に行えます。例えばCloudWatchでは以下のようなアラームを設定することが可能です。
- エラー率が5%を超えた場合
- P95レイテンシが500msを超えた場合
さらに、APIのレート制限到達回数やスロットリング発生頻度を監視することで、今後のキャパシティ計画に活かすことができます。
共通の運用監視ポイント
WebhookとAPIのどちらを使う場合でも、共通して監視すべきポイントがいくつかあります。
まず、サーバーのCPUやメモリ負荷は必須の監視項目です。急激な負荷増加は、システム全体のパフォーマンス低下やダウンタイムの前兆であることが多いため早期発見が重要です。
次に、接続数の急増にも注意が必要です。通常とは異なるパターンで接続数が増加した場合、DoS攻撃の兆候である可能性があります。こうした兆候をいち早く検知し迅速に対策を講じることが重要です。
また、リリース後のエラー率の動向にも注意しましょう。新機能をリリースした直後にエラー率が急増する場合、迅速なロールバックや修正対応が求められます。
以下の3つのポイント、をきちんと監視することで、WebhookでもAPIでもシステムの安定稼働のための堅固な基盤を築くことができます。
- CPU/メモリ負荷
- 接続数の異常増加
- リリース後のエラー率上昇
監視ダッシュボードにはこれらの指標を常に表示し、閾値を超えた際には即座にアラートが発報されるよう設定することを強くおすすめします。
まとめ
本記事ではWebhookとAPIの基本的な違いから、ネットワーク負荷、セキュリティ対策、リトライ設計、そして運用監視に至るまで、さまざまな観点から詳しく比較してきました。
システム設計を行ううえでは、それぞれの特性をしっかり理解し、用途や要件に応じて適切な方式を選ぶことが非常に大切です。
また、どちらの方式を選択する場合でも、適切なエラーハンドリングと運用監視体制を構築することが、安定したシステム運用を支える鍵となります。
ぜひ今回のポイントを参考に、より信頼性の高いシステム設計に活かしてください。

